计量经济学论文_计量经济学论文选题方向
1.计量经济学论文的有关问题 老师布置了一篇计量经济论文,是 拉动内需的税收政策研究 我想了很久,考虑了
2.有什么好的计量经济学论文题目?简单一点的
3.计量经济学实验报告
4.有什么容易分析的计量经济学论文选题吗?
5.你好,可以也给我发一份计量经济学的论文吗?不要太专业的,就是平时作业
6.本科生没有学过计量经济学如何写一篇实证分析类的经济学毕业论文?
7.求计量经济学论文
你的计量经济学论文准备往什么方向写,选题老师审核通过了没,有没有列个大纲让老师看一下写作方向?
老师有没有和你说论文往哪个方向写比较好?写论文之前,一定要写个大纲,这样老师,好确定了框架,避免以后论文修改过程中出现大改的情况!!
学校的格式要求、写作规范要注意,否则很可能发回来重新改,你要还有什么不明白或不懂可以问我,希望你能够顺利毕业,迈向新的人生。
1,论文应该是单一主题还是面面俱到?
大学生碰到的第一个诱惑是想在论文里写很多东西。比如有个学生对文学感兴趣,他第一个念头就是给论文起一个《今日文学》这样的标题。如果迫不得已要缩小范围,他会选择《从战后到70年代的西班牙文学》。
这类论文是非常危险的。这种题目会让即使是成熟得多的研究者们也直挠头的。对一个20多岁的大学生来说这是不可能完成的挑战。它要么会变成各种名字和主流观点的简单罗列,要么对原始材料的引用会有失偏颇(这常常是由于省略了不该省略的东西引起的)。1961年,当代作家冈萨罗·托兰特·巴雷斯特写了一本《当代西班牙文学面面观》(瓜德拉玛版),然而,如果这是一篇博士论文的话,人们是一定会把它毙了的,虽然它厚达几百页。它被指责出于疏忽或者无知而没有提到一些被认为非常重要的人物的名字,或者他有时会花一整个章节来写一些“不怎么样”的作家,而对于一些被认为是“重要人物”的则只给了寥寥数笔。当然,我们知道该作者的历史学识以及批评能力都是得到认可的,所以这些遗漏或者比例失调都是有意为之,对某个人物避而不谈比为他洋洋洒洒地写上一整页更能够说明问题。不过如果同样的事情发生在一个二十二岁的大学生身上,谁又能保证他的沉默背后不是别有用心呢?或者他的避而不谈是因为会在其他地方花上几页纸来讨论这个问题?或者这个作者到底知不知道应该怎样写啊?
写这种论文的学生常常会向评审委员会的成员抱怨说他们没看懂自己的意思,但是那些成员实际上“无法”看懂他的意思,所以一篇面面俱到的论文常常被看作是傲慢的表现。并不是说(论文中所体现的)学术上的傲慢就一定要被否定掉,我们甚至可以说但丁是个糟糕的诗人,但必须至少先写个300页,对但丁的文本进行深入的分析之后才能说。而这些在一片面面俱到的论文中是看不到的。正因为这样,对于一个大学生来说,与其写什么《从战后到70年代的西班牙文学》,还不如选一个更切实际的低调一点的题目。
我可以很直接地告诉你什么才是好题目,它并不是《阿尔代科阿的》,而是《“天堂鸟”的两种不同版本》。听上去是不是有点无趣?可能吧,不过那会是更加有趣的挑战。
只要好好想一想你就会看到归根到底这是一个如何讨巧的问题。如果写一篇关于四十年的文学的面面俱到的论文,学生将会面对各种可能的反对声音。如果有个提案人或者评审委员会的成员正好想要标榜自己知道某个不太知名的作家,如果那个学生正好又没有把那个作家包括在论文内,他将如何面对前者的发难呢?只要每个评审委员会的成员在看目录时都发现了三个没有被提到的人,那个学生就将在一顿猛烈的轰炸中变得脸色惨白,他的论文顿时好像变成了屁话连篇。相反的,如果学生认真地选择一个范围很小的题目,他就只需要牢牢把握住一份评审委员会大多数成员都不知道的材料就可以了。我并不是在兜售什么下三滥的伎俩,这的确是一种伎俩,但并不低俗,而且它很管用。只要学位申请人以“专家”的面目出现在不如他专业的公众面前,而且看得出为了成为专家他是花了一番心血的,这样占一点便宜是无可厚非的。
在这两种极端之间(也就是写四十年文学史的面面俱到的论文以及两种文本之间区别这样严格的单一主题论文)存在着许多中间形式。比如我们可以写《四十年代先锋派文学家的经历》或者《胡安·贝内特和桑切斯·菲尔罗西奥对地理的文学处理》,甚至《卡洛斯·埃德蒙多·德·奥利,埃杜瓦多·奇恰罗以及格罗里亚·富埃尔特斯:三位后岛屿诗人的异同》。
我们来看一下一本小册子上的一段话,虽然那是科学领域的,但它所给出的建议适用于所有学科:
比如说,《地质学》这个题目就太宽泛了。《火山学》是地质学的一个分支,但是也太大了。《墨西哥的火山》是个不错的着手点,但是同样不够深入。我们把范围在缩小一点就有可能引出非常有价值的研究了:《波波卡莱佩伊尔火山的历史》(科尔特斯的征服者中的某人可能在1591年登上过那里,直到1702年它都没有猛烈喷发过)。一个范围更小,所涉及年份更少的题目是《帕里库丁火山的诞生和死亡》(它的生命仅仅从1943年2月20日延续到了到1952年3月4日)。
好吧,我还是推荐最后一个题目。因为到了这个地步,只要申请人能够对那座不幸的火山知无不言,言无不尽就可以了。
很久以前,有个学生跑来跟我说他要写一篇题为《当代思想中的符号》的论文。这样的论文是不可能的。连我也不知道“符号”到底指的是什么,实际上这个词在不同的作者那里具有不同的意思,有时,两个作者会用它来表达意思完全相反的两件东西。我们只要考虑一下形式逻辑学家或者数学家所理解的“符号”,它们是没有意义的,在计算公式中占据特定位置,具有特定功能的东西(比如代数公式中的a,b,x,y神马的),而其他一些作者则可能把它们看做充满了模棱两可含义的东西,比如梦中出现的那些图像,它们可能指一棵树,或者性器官,或者想要长大的愿望等等。所以,我们怎么能把这个作为论文的题目呢?我们必须分析当代文化中所有关于符号的理论,列出它们的共同点和不同点,在它们的不同点里寻找所有作者和理论共有的基本的单一概念,看一下这些不同在不同理论中是否是不相容的。没有当代的哲学家,语言学家或者心理分析学家能够令人满意地解决这个问题。一个初出茅庐的大学生,即使他早慧也只不过接受了最多六七年的成年人的教育,他又怎么能够完成这样的研究呢?最多又是一个像托兰特·巴雷斯那样有失偏颇的东西了。或者他会提出自己的关于符号的理论,而把前人所说的东西晾在一边,下一节我们还要再来说说这种做法值得商榷的地方。我和这个学生交谈了一会儿,我建议他可以写弗洛伊德和荣格的符号,他需要忘记其他各种观点,专心考虑上面的两个作者。可惜这个学生不懂德语(关于语言的问题我们会在第五节谈到)。最后我们决定将题目定为《皮尔士,弗莱和荣格的符号概念》,论文将讨论这三位分别是哲学家,评论家和心理分析家的不同作者那里的三个用同一个词表示的不同概念。由于他们用了同一个词结果造成了混乱,常常有人把其中一位的概念安到另一个人身上。在文章的最后,作为设的结论,这个学生试图在这些同名异义的概念间寻找平衡,找出它们的相似点。他还提到了一些自己所知道的其他作者,但表示因为论文篇幅所限就无法对他们更多展开了。这样,虽然他的论文只提到了作者X,Y,Z,但没有人能够指责他没有考虑作者K。也没有人能指摘他对引述的那些其他作者不够详细,因为那是在论文的结尾处顺带说一下的,而论文的主体是讨论题目中所出现的那三位作者。
现在我们看到了论文不必非要恪守单一主题,一篇面面俱到的论文也可以变得中规中矩,让所有人都接受。
需要指出的是,“单一”这个词的意思比我们在这里所用的要多得多。一篇单一论文只涉及一个主题,与“XXX的历史”或者一本手册或者一本百科全书完全相反。从这个意义上来说,《中世纪作家的“颠倒的世界”这个主题》应该也是一个单一主题。它涉及许多作家,但全都是围绕一个具体的主题(从他们想象的设到所举的例子,悖论和寓言,比如在天上飞的鱼,在水里游的鸟神马的)。看上去这是一个理想的单一主题。但事实上,为了写这样一篇论文,我们需要讨论所有与这个主题有关的作者,特别是那些没有得到公认的不知名作者。所以这个题目还是要被归在“具有单一主题的面面俱到式论文”中,它是很难写的,需要准备无数的材料。如果有人一定要写的话,我建议把题目改成《卡洛林王朝时期的诗人的“颠倒的世界”这个主题》,范围一缩小,我们就知道该到哪儿不该到哪儿去寻找材料了。
当然,面面俱到的论文写起来更加有劲,毕竟花一两年甚至更长的时间研究一位作家显得很无聊。但是我们要明白,写一篇严格意义上的单一主题的论文并不意味着在视角上不能做到面面俱到。写一篇关于阿尔德科阿的的论文需要我们深入了解西班牙的现实主义,我们还需要读桑切斯·菲尔罗西奥或者加西亚·奥尔特拉诺,需要研究阿尔德科阿度过的美洲以及古典文学。只有把作者放到全景当中我们才能理解和诠释他。但是把全景用作背景和绘出一幅全景的图画是两回事。前者只是以一片田野和一条河流作为背景画了一幅骑士的肖像,后者则要画许多田野,山谷和河流。我们必须要改变技法,或者用摄影的术语来说,改变焦距。从单一作者的角度出发拍摄的全景是有点失焦的,不完整的和劣质的。
最后我们要记住下面这个基本结论:范围越小,干起活来就越是省心和安心。单一主题由于面面俱到,论文看起来最好像是随笔,而不是历史或者百科全书。
计量经济学论文的有关问题 老师布置了一篇计量经济论文,是 拉动内需的税收政策研究 我想了很久,考虑了
计量经济学
期末实验报告
实验名称:大中城市城镇居民人均消费支出与其影响因素的分析
姓 名:
学 号:
班 级:
指导教师:
时 间:
23个城市城镇居民人均消费支出
与其影响因素的分析
一、 经济理论背景
近几年来,中国经济保持了快速发展势头,投资、出口、消费形成了拉动经济发展的“三架马车”,这已为各界所取得共识。通过建立计量模型,运用计量分析方法对影响城镇居民人均消费支出的各因素进行相关分析,找出其中关键影响因素,以为政策制定者提供一定参考,最终促使消费需求这架“马车”能成为引领中国经济健康、快速、持续发展的基石。
二、 有关人均消费支出及其影响因素的理论
我们主要从以下几个方面分析我国居民消费支出的影响因素:
①、居民未来支出预期上升,影响了居民即期消费的增长
居民的被动储蓄直接导致购买力的巨大分流, 从而减弱对消费品的即期需求,严重地影响了居民即期消费的增长,进而导致有效需求的不足,最终导致经济增长的乏力。90年代末期以来,我国的医疗、养老、失业保险、教育等一系列改革措施集中出台,原有的体制被打破,而新的体制尚未建立健全,因此目前的医疗、养老、失业保险、教育体制对居民个人支出的压力较大,而且基本上都是硬性支出,支出的不确定性也很大,导致居民目前对未来支出预期的上升。
②、商品供求结构性矛盾依然突出
从消费结构上看,我国消费品市场已发生了新的根本性变化:居民低层次消费已近饱和,而更高水平的消费又未达到。改革开放20多年来,城乡居民经过了一个中档耐用消费品的普及阶段后,目前老百姓的收入消费还不足以形成一个新的、以高档产品为内容的主导性消费热点,如轿车、住房等还远不能纳入大多数人的消费主流,居民现有的购买力不能形成推动主导消费品升级的动力。
③、物价总水平持续在低水平运行,通货紧缩的压力较大,不利于消费的增长
加入WTO之后,随着关税的降低和进口规模的扩大,国外产品对我国市场的冲击将进一步加大,国际价格紧缩对国内价格变化将产生负面影响。物价的持续下降,不利于居民的消费增长。因为从居民的消费心理上看,买涨不买降是居民购物的习惯心理。由于居民对物价有进一步下降的预期,因此往往推迟消费,不利于居民消费的增长。另外,从统计上分析,由于物价的下降,名义消费增长往往低于实际消费的增长,这在一定程度上也不利于消费增长幅度的提高。
④、我国现阶段没有形成大的消费热点,难以带动消费的快速增长
经过近几年的培育和发展,我国目前已经形成了住房消费、居民汽车消费、通信及电子产品的消费、节日消费及旅游消费等一些消费亮点,可以促进消费的稳定增长,但始终未能形成大的消费热点,因此不能带动消费的高速增长。
三、 相关数据收集
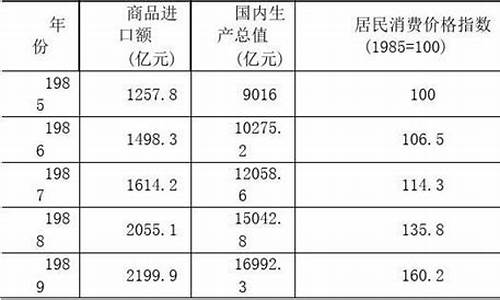
相关数据均来源于2006年《中国统计年鉴》:
23个大中城市城镇居民家庭基本情况
地区 平均每户就业人口(人) 平均每一就业者负担人数(人) 平均每人实际月收入(元) 人均可支配收入(元) 人均消费支出(元)
北京 1.6 1.8 1865.1 1633.2 1187.9
天津 1.4 2.0 2010.6 1889.8 939.8
石家庄 1.4 2.0 1061.3 1010.0 722.9
太原 1.3 2.2 1256.9 1159.9 789.5
呼和浩特 1.5 1.9 1354.2 1279.8 772.7
沈阳 1.3 2.1 1148.5 1048.7 812.1
大连 1.6 1.8 1269.8 1133.1 946.5
长春 1.8 1.7 1156.1 1016.1 690.2
哈尔滨 1.4 2.0 992.8 942.5 727.4
上海 1.6 1.9 1884.0 1686.1 1505.3
南京 1.4 2.0 1536.4 1394.0 920.6
杭州 1.5 1.9 1695.0 1464.9 1264.2
宁波 1.5 1.8 1759.4 1543.2 1271.4
合肥 1.6 1.8 1042.5 950.1 686.9
福州 1.7 1.9 1172.5 1059.4 942.8
厦门 1.5 1.9 1631.7 1394.3 998.7
南昌 1.4 1.8 1405.0 1321.1 665.4
济南 1.7 1.7 1491.3 1356.8 1071.4
青岛 1.6 1.8 1495.6 1378.5 1020.7
郑州 1.4 2.1 1012.2 954.2 750.3
武汉 1.5 2.0 1052.5 2.2 853.1
长沙 1.4 2.1 1256.9 1148.9 986.8
广州 1.7 1.8 1898.6 1591.1 1215.1
四、 模型的建立
根据数据,我们建立多元线性回归方程的一般模型为:
其中:
——人均消费支出
——常数项
——回归方程的参数
——平均每户就业人口数
——平均每一就业者负担人口数
——平均每人实际月收入
——人均可支配收入
——随即误差项
五、实验过程
(一)回归模型参数估计
根据数据建立多元线性回归方程:
首先利用Eviews软件对模型进行OLS估计,得样本回归方程。
利用Eviews输出结果如下:
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:08
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C -1682.180 1311.506 -1.282633 0.2159
X1 564.3490 395.2332 1.427889 0.1704
X2 569.1209 379.7866 1.498528 0.1513
X3 1.552510 0.629371 2.466766 0.0239
X4 -1.180652 0.742107 -1.590947 0.1290
R-squared 0.721234 Mean dependent var 945.2913
Adjusted R-squared 0.659286 S.D. dependent var 224.1711
S.E. of regression 130.8502 Akaike info criterion 12.77564
Sum squared resid 308191.9 Schwarz criterion 13.02249
Log likelihood -141.9199 F-statistic 11.64259
Durbin-Watson stat 2.047936 Prob(F-statistic) 0.000076
根据多元线性回归关于Eviews输出结果可以得到参数的估计值为: , , , ,
从而初步得到的回归方程为:
Se= (1311.506) (395.2332) (379.7866) (0.629371) (0.742107)
T= (-1.282633) (1.427889) (1.498528) (2.466766) (-1.590947)
F=11.64259 df=18
模型检验:由于在 的水平下,解释变量 、 、 的检验的P值都大于0.05,所以变量不显著,说明模型中可能存在多重共线性等问题,进而对模型进行修正。
(二)处理多重共线性
我们用逐步回归法对模型的多重共线性进行检验和处理:
X1:
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:28
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C 153.8238 518.6688 0.296574 0.76
X1 523.0964 341.4840 1.531833 0.1405
R-squared 0.100508 Mean dependent var 945.2913
Adjusted R-squared 0.057675 S.D. dependent var 224.1711
S.E. of regression 217.6105 Akaike info criterion 13.68623
Sum squared resid 994441.2 Schwarz criterion 13.784
Log likelihood -155.3917 F-statistic 2.346511
Durbin-Watson stat 1.770750 Prob(F-statistic) 0.140491
X2:
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:29
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C 1756.641 667.2658 2.632596 0.0156
X2 -424.1146 347.95 -1.218861 0.2364
R-squared 0.066070 Mean dependent var 945.2913
Adjusted R-squared 0.0215 S.D. dependent var 224.1711
S.E. of regression 221.7371 Akaike info criterion 13.72380
Sum squared resid 1032515. Schwarz criterion 13.82254
Log likelihood -155.8237 F-statistic 1.485623
Durbin-Watson stat 1.887292 Prob(F-statistic) 0.236412
X3:
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:29
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C 182.8827 137.8342 1.326831 0.1988
X3 0.540400 0.095343 5.667960 0.0000
R-squared 0.604712 Mean dependent var 945.2913
Adjusted R-squared 0.585888 S.D. dependent var 224.1711
S.E. of regression 144.2575 Akaike info criterion 12.86402
Sum squared resid 437014.5 Schwarz criterion 12.96276
Log likelihood -145.9362 F-statistic 32.12577
Durbin-Watson stat 2.064743 Prob(F-statistic) 0.000013
X4:
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:30
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C 184.7094 161.8178 1.141465 0.2665
X4 0.596476 0.124231 4.801338 0.0001
R-squared 0.523300 Mean dependent var 945.2913
Adjusted R-squared 0.500600 S.D. dependent var 224.1711
S.E. of regression 158.4178 Akaike info criterion 13.05129
Sum squared resid 527020.1 Schwarz criterion 13.15003
Log likelihood -148.0898 F-statistic 23.05284
Durbin-Watson stat 2.037087 Prob(F-statistic) 0.000096
由得出的数据可以看出, 的调整的判定系数最大,因此首先把 引入调整的方程中,然后在分别引入变量 、 、 进行OLS得:
X1、X3
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:32
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C -222.8991 345.9081 -0.644388 0.5266
X1 289.8101 227.2070 1.275533 0.2167
X3 0.517213 0.095693 5.404899 0.0000
R-squared 0.634449 Mean dependent var 945.2913
Adjusted R-squared 0.5894 S.D. dependent var 224.1711
S.E. of regression 142.1510 Akaike info criterion 12.87276
Sum squared resid 404138.2 Schwarz criterion 13.02087
Log likelihood -145.0368 F-statistic 17.35596
Durbin-Watson stat 2.032110 Prob(F-statistic) 0.000043
X2、X3
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:33
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C 239.5536 531.1435 0.451015 0.6568
X2 -27.00981 244.0392 -0.110678 0.9130
X3 0.536856 0.102783 5.223221 0.0000
R-squared 0.604954 Mean dependent var 945.2913
Adjusted R-squared 0.565449 S.D. dependent var 224.1711
S.E. of regression 147.7747 Akaike info criterion 12.95036
Sum squared resid 436747.0 Schwarz criterion 13.09847
Log likelihood -145.9292 F-statistic 15.31348
Durbin-Watson stat 2.063247 Prob(F-statistic) 0.000093
X3、X4
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:34
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C 331.7015 142.5882 2.326290 0.0306
X3 1.766892 0.553402 3.192782 0.0046
X4 -1.473721 0.656624 -2.244390 0.0363
R-squared 0.684240 Mean dependent var 945.2913
Adjusted R-squared 0.652664 S.D. dependent var 224.1711
S.E. of regression 132.1157 Akaike info criterion 12.72634
Sum squared resid 349091.0 Schwarz criterion 12.87445
Log likelihood -143.3529 F-statistic 21.66965
Durbin-Watson stat 2.111635 Prob(F-statistic) 0.000010
由数据结果可以看出,引入X4时方程的调整判定系数最大,且解释变量均通过了显著性检验,再分别引入X1、X2进行分析。
X1、X3、X4
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:37
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C 193.6693 403.8464 0.479562 0.6370
X1 89.29944 243.6512 0.366505 0.7180
X3 1.652622 0.646003 2.558228 0.0192
X4 -1.345001 0.757634 -1.775265 0.0919
R-squared 0.686457 Mean dependent var 945.2913
Adjusted R-squared 0.636950 S.D. dependent var 224.1711
S.E. of regression 135.0712 Akaike info criterion 12.80625
Sum squared resid 346640.3 Schwarz criterion 13.00373
Log likelihood -143.2719 F-statistic 13.86591
Durbin-Watson stat 2.082104 Prob(F-statistic) 0.000050
X2、X3、X4
Dependent Variable: Y
Method: Least Squares
Date: 12/11/07 Time: 16:38
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C 62.60939 489.2088 0.127981 0.8995
X2 134.1557 232.9303 0.575948 0.5714
X3 1.886588 0.600027 3.144175 0.0053
X4 -1.596394 0.701018 -2.277251 0.0345
R-squared 0.689658 Mean dependent var 945.2913
Adjusted R-squared 0.640657 S.D. dependent var 224.1711
S.E. of regression 134.3798 Akaike info criterion 12.79599
Sum squared resid 343100.8 Schwarz criterion 12.99347
Log likelihood -143.1539 F-statistic 14.07429
Durbin-Watson stat 2.143110 Prob(F-statistic) 0.000046
由输出结果可以看出,在 的水平下,解释变量 、 的检验的P值都大于0.05,解释变量不能通过显著性检验,因此可以得出结论模型中只能引入X3、X4两个变量。则调整后的多元线性回归方程为:
Se= (142.5882) (0.553402) (0.656624)
T= (2.326290) (3.192782) (-2.244390)
F=21.66965 df=20
(三).异方差性的检验
对模型 进行怀特检验:
White Heteroskedasticity Test:
F-statistic 1.071659 Probability 0.399378
Obs*R-squared 4.423847 Probability 0.351673
Test Equation:
Dependent Variable: RESID^2
Method: Least Squares
Date: 12/11/07 Time: 16:53
Sample: 1 23
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
C 34247.50 128527.9 0.266460 0.7929
X3 247.9623 628.1924 0.394723 0.67
X3^2 -0.071268 0.187278 -0.380548 0.7080
X4 -333.6779 714.3390 -0.467114 0.6460
X4^2 0.121138 0.229933 0.526841 0.6047
R-squared 0.192341 Mean dependent var 15177.87
Adjusted R-squared 0.012861 S.D. dependent var 23242.54
S.E. of regression 23092.59 Akaike info criterion 23.12207
Sum squared resid 9.60E+09 Schwarz criterion 23.36892
Log likelihood -260.9038 F-statistic 1.071659
Durbin-Watson stat 1.968939 Prob(F-statistic) 0.399378
由检验结果可知, ,由White检验知,在 时,查 分布表,得临界值 (20)=30.1435,因为 < (5)= 30.1435,所以模型中不存在异方差。
(四).自相关的检验
由模型的输出结果可知,估计结果都比较满意,无论是回归方程检验,还是参数显著性检验的检验概率,都显著小于0.05,D-W值为2.111635,显著性水平 =0.05下查Durbin-Watson表,其中n=23,解释变量的个数为2,得到下限临界值 ,上限临界值 , =1.543<D-W=2.111635<4 ,由DW检验决策规则可知,该模型不存在自相关问题。
六、对模型进行分析和解释经济学意义
回归方程的意义为:当平均每人实际月收入不变时,人均可支配收入每增加一个单位,人均消费支出减少1.473721个单位;当人均可支配收入不变时,平均每人实际月收入每增加一个单位,人均消费支出增加1.766892个单位。
七、 就模型所反映的问题给出针对性的政策建议或结论
对于我国人均消费支出的分析中,可以看出我国在过去的几年里经济发展稳健,但是由于种种原因导致我国经济的现状存在一定的问题,如不完善的社会保障制度导致消费结构不合理;过高的居民储蓄存款影响居民消费倾向;消费品生产行业投资方向失误和低效率引起国内市场消费梗阻;保守的消费观念和消费政策的制约;教育支出比重过大影响居民消费倾向 。对此我们国家应该在以下几个方面对居民消费中存在的问题进行对策研究
(一)建立和完善社会保障制度,增强居民消费信心
(二)培育新的消费热点,拓展居民的消费领域
(三)促使商品消费从自我积累型向信用支持型转变
(四)分层次促进居民消费
(五)破解影响消费结构优化的政策制约
(六)化解有效供给不足与产品相对过剩的矛盾
有什么好的计量经济学论文题目?简单一点的
因变量是要反应内需的,可以以个人消费或者用GDP减掉G,I,X-M
自变量的话你想要反应的是税收政策,所以可以找下世界各个国家的税收政策的不同,设立dummies
剩下的就是控制变量了,各个国家消费水平不同等等的用GDP啊,PPP购买力之类的控制下
计量经济学实验报告
我国旅游经济的因素分析
我国旅游业发展状况分析
我国居民消费增长模型
我国经济增长与周期波动
我国经济增长对能源消耗的依赖
公共投资取向与经济增长分析
三大产业的发展与城镇居民家庭消费支出
餐饮业区域市场潜力的影响因素分析
资本结构主要影响因素的再探析
国债发行规模的计量经济分析
工资收入差异分析
城镇人均收入与人均通讯消费分析
影响居民消费水平的因素分析
影响就业人数的因素的计量分析
影响大学生就业问题的因素分析
影响股价指数的因素分析
影响我国电力产量的因素分析
影响中国汽车产量的多因素分析
私家车拥有量的计量分析
我国汽车需求的因素分析
有什么容易分析的计量经济学论文选题吗?
计量经济学实验报告参考格式:
一、介绍主题,提出感兴趣的主要问题
实验报告的前几段应该对主题进行有趣的描述。研究项目的介绍部分应该包括以下两个部分(按顺序排列):
1、主题说明;
2、对方法的描述。
二、回顾现有文献
其他研究人员可能已经研究了相关主题,所以报告的一个部分应该回顾关于这个主题的其他研究。
三、描述概念或理论框架
计量经济学的应用研究不同于统计分析,其特征之一是支持实证工作的理论结构。
四、解释计量经济学模型
开发了模型的理论结构之后,同学需要将其与经验、方法(也就是统计分析和观察方法)联系起来,这种方法在形式上被称为经济计量模型。
五、讨论估算方法
因为估计通常是设某些统计条件成立,所以从计量经济学模型到估计可能并不完全简单。
六、详细描述数据
详细描述所使用的数据。要解决这些问题:
1、数据集是如何获得的及其来源;
2、数据的性质;
3、数据覆盖的时间范围;
4、数据收集的方式和频率;
5、观察到的结果;
6、计量经济学模型中使用的任何变量的汇总统计数据(平均值、标准差等)。
七、解释报告结果
读者可能不太了解计量经济学模型的规格、变量的规模以及其他相关信息,因此同学需要为读者提供相应的解释。
八、总结学到的东西
研究项目的结论应该综合结果,并解释其如何与报告的主要问题相关联。
你好,可以也给我发一份计量经济学的论文吗?不要太专业的,就是平时作业
下面,给到一些题目,你觉得对你简单的就可以写。
1.杨海文:空间计量模型的选择、估计及其应用江西财经大学,2015。
2.何煜辉:我国企业合并商誉会计计量研究北京交通大学,2015。
3.陈天约:投资性房地产公允价值计量对企业财务绩效的影响华东理工大学,2015。
4.张春燕:公允价值计量模式在投资性房地产中应用的实证研究武汉科技大学,2014。
5.陈晨:投资性房地产公允价值计量动因与经济后果研究中国矿业大学,2014。
6.张甜:公允价值计量模式在投资性房地产中的应用研究厦门大学,2014。
7.赵轶:金融集聚、空间溢出与区域经济增长西南财经大学,2014。
8.李蓉:自创商誉的计量及其应用研究北京交通大学,2014。
9.杨友焱:投资性房地产公允价值计量的应用及财务影响研究重庆大学,2013。
10.胡庭清:非活跃市场环境下公允价值会计计量问题研究湖南大学,2012。
当然,最好是结合题目的同时,结合自己的现实情况,加入自己的想法,进行创新。
本科生没有学过计量经济学如何写一篇实证分析类的经济学毕业论文?
计量经济学论文作业对于学生们来说是比较常见的,作为作业来讲,它是有一定难度的,建议同学咨询专业老师进行指导。
计量经济学论文作业辅导
计量经济学论文作业写作步骤1、问题的提出
2、理论模型的设计
3、模型参数估计与回归结果基本分析
4、模型的计量经济学检验与修正
5、模型的应用与对策建议
求计量经济学论文
本科生没有学过计量经济学,但却要写一篇实证分析类的经济学毕业论文,那么这个时候就可以去请教论文指导老师,看看指导老师能否帮助自己解决一些难题,如若不行则需要自己回过头再去学习,学完之后再来写这个论文。
不知道题主具体要写哪方面的东西,如果是面板数据的话那stata还行,如果是时序列分析的话推荐用Eviews,如果是偏宏观理论的模型那比较推荐matlab。
写论文注意事项:
1、论文里面千万不可以出现“我”这个词,论文具有科学的严肃性、严谨性,避免出现“我”人称代词。当然现在也有很多的论文改成了“笔者”呢,实际上,用“本文”来替代比较是聪明人的做法,也是在各类文献中出现频率最高的词汇。
2、论文写作过程中避免出现感叹号,论文应以陈述语句为主,出现语气叹词瞬间降低论文的层次,问句主要在写文章的结构和结论的时候使用,其他的地方能少就少。
3、杜绝排比句,排比句很没有逻辑,尤其是文科论文写作过程中,出现排比句会让别人将你的论文当成作文,切记论文不是作文。
4、直接引用不超过文章全文的百分之十五到二十,间接引用不超过百分之三十。直接引用和间接引用主要放在文章的前人研究成果的部分。避免直接引用,一个小技巧就是把直接引用放在注解里面。
计量经济学课程论文
小组成员:
组长:
指导教师:
日期:2010/年5月27日
2006年我国各城市的GDP变动的多因素分析
摘要:本文主要通过对各城市同一时期的GDP进行多因素分析,建立以各城市同一时期的GDP为被解释变量,以其它可量化横截面数据作为解释变量建立多元线性回归模型,从而对各城市同一时期的GDP进行数量化分析。
关键词:GDPY(亿元) 多因素分析 模型 计量经济学 检验
一、引言部分
GDP(国内生产总值)指一个国家(或地区)所有常住单位在一定时期内生产活动的最终成果,从价值形态看,它是所有常住单位在一定时期内生产的全部货物和服务价值超过同期中间投入的全部非固定资产货物和服务价值的差额,即所有常住单位的增加值之和。GDP在创造的同时也被相应的生产要素分走了,主要体现为劳动报酬和利润。在现代社会还要以税收的形式拿走一部分GDP。本文主要研究就业人数L(万人)、各地区资本形成总额K(亿元)剔除价格影响因素即商品零售价格指数P(上年=100)之后对各城市同一时期的GDP的影响。
二、文献综述
注: 2006年各城市同一时期的GDP总量的数据来源于《中国统计年鉴2007》;
2006年就业人数L(万人)的数据来源于《中国统计年鉴2007》;
2006年资本形成总额K(亿元)的数据来源于《中国统计年鉴2007》,本表按2006年价格计算;
2006年商品零售价格指数P(上年=100)的数据来源于《中国统计年鉴2007》;
三、研究目的
通过研究各个城市在同一时期的GDP建立以各城市同一时期的GDP为被解释变量,以其它可量化横截面数据作为解释变量建立多元线性回归模型,从而对各城市同一时期的GDP进行数量化分析。掌握建立多元回归模型和比较、筛选模型的方法。
四、实验内容
根据生产函数理论,生产函数的基本形式为: 。其中,L、K分别为产出GDP的过程中投入的劳动与资金,本文未考虑时间变量 即技术进步的影响。上表列出了我国2006年我国各个城市的GDP的有关统计资料;其中产出Y为各城市同一时期的GDP(可比价),L、K分别为2006年年末职工人数和各地区资本形成总额(可比价)。
五、建立模型并进行模型的参数估计、检验及修正
(一) 我们先建立Y1与L的关系模型:
其中,Y1——各个城市在同一时期的实际GDP(亿元)
L——2006年年末职工人数(万人)
模型的参数估计及其经济意义、统计推断的检验
利用EVIEWS软件,经回归分析,作出Y1与L的散点图如下:
利用EVIEWS软件,用OLS方法估计得:
Dependent Variable: Y1
Method: Least Squares
Date: 05/27/10 Time: 14:45
Sample: 1 36
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C -1647.264 517.2169 -3.184861 0.0034
L 14.99417 0.712549 21.04299 0.0000
R-squared 0.938534 Mean dependent var 7387.9
Adjusted R-squared 0.936415 S.D. dependent var 6367.139
S.E. of regression 1605.545 Akaike info criterion 17.66266
Sum squared resid 74755513 Schwarz criterion 17.75517
Log likelihood -271.7712 F-statistic 442.8073
Durbin-Watson stat 1.503388 Prob(F-statistic) 0.000000
可见,L的t值显著,且系数符合经济意义。从经济意义上讲,劳动每增加一单位,都可以使实际GDP相应增加14.9941, 这在一定条件下可以实现。另外,修正可决系数为0.936415,F值为442.8073,明显通过了F检验。且L的P检验值为0,小于0.05,所以通过了P值检验
(二)建立Y1与K1的关系模型:
其中,Y1——各个城市在同一时期的实际GDP(亿元)
K1——各地区资本形成总额(实际投入额)(亿元)
模型的参数估计及其经济意义、统计推断的检验
利用EVIEWS软件,经回归分析,作出Y1与K1的散点图如下:
利用EVIEWS软件,用OLS方法估计得:
Dependent Variable: Y1
Method: Least Squares
Date: 05/27/10 Time: 17:16
Sample: 1 36
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C -705.0563 393.0357 -1.793873 0.0833
K1 2.241106 0.086751 25.83385 0.0000
R-squared 0.958357 Mean dependent var 7387.9
Adjusted R-squared 0.956921 S.D. dependent var 6367.139
S.E. of regression 1321.537 Akaike info criterion 17.27332
Sum squared resid 50647333 Schwarz criterion 17.36583
Log likelihood -265.7364 F-statistic 667.3880
Durbin-Watson stat 1.6910 Prob(F-statistic) 0.000000
可见,K1的t值显著,且系数符合经济意义。从经济意义上讲,资本每增加一单位,都可以使实际GDP相应增加2.241106, 这在一定条件下可以实现。另外,修正可决系数为0.956921,F值为667.3880,明显通过了F检验。且K1的P检验值为0,小于0.05,所以通过了P值检验
通过两个模型的可绝系数 、调整可决系数 、T检验、F检验、P值检验的比较,明显的 ,Y1与K1的关系模型优于Y1与L的关系模型。因此,在以Y1与K1的关系模型为基础模型的条件下,建立二元关系模型。
(三)建立Y1与K1和L的二元关系模型
其中,Y1——各个城市在同一时期的实际GDP(亿元)
K1——各地区资本形成总额(实际投入额)(亿元)
L——2006年年末职工人数(万人)
利用EVIEWS软件,用OLS方法估计得
Dependent Variable: Y1
Method: Least Squares
Date: 05/27/10 Time: 17:23
Sample: 1 36
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C -1369.643 303.2218 -4.516968 0.0001
K1 1.336796 0.176104 7.590936 0.0000
L 6.522268 1.190606 5.478107 0.0000
R-squared 0.9900 Mean dependent var 7387.9
Adjusted R-squared 0.8464 S.D. dependent var 6367.139
S.E. of regression 934.3899 Akaike info criterion 16.60943
Sum squared resid 24446367 Schwarz criterion 16.74820
Log likelihood -254.4462 F-statistic 682.5040
Durbin-Watson stat 1.633165 Prob(F-statistic) 0.000000
可见,K1和L的t值显著,且系数符合经济意义。从经济意义上讲,资本每增加一单位,都可以使实际GDP相应增加。另外,修正可决系数为0.8464,F值为682.5040,明显通过了F检验。且K1和L的P检验值为0,均小于0.05,所以通过了P值检验。
通过两个模型的可绝系数 、调整可决系数 、T检验、F检验、P值检验的比较,明显的 ,Y1与K1和L的关系模型优于Y1与K1的关系模型。因此,建立二元关系模型更符合实际经济情况。
(四)建立非线性回归模型——C-D生产函数。
C-D生产函数为: ,对于此类非线性函数,可以用以下两种方式建立模型。
方式1:转化成线性模型进行估计;
在模型两端同时取对数,得:
在EViews软件的命令窗口中依次键入以下命令:
GENR LNY1=log(Y1)
GENR LNL=log(L)
GENR LNK1=log(K1)
LS LNY1 C LNL LNK1
则估计结果如图所示。
Dependent Variable: LNY1
Method: Least Squares
Date: 05/27/10 Time: 17:29
Sample: 1 36
Included observations: 31
Variable Coefficient Std. Error t-Statistic Prob.
C 0.242345 0.198180 1.222853 0.2316
LNK1 0.666500 0.082707 8.058538 0.0000
LNL 0.493322 0.088128 5.5775 0.0000
R-squared 0.988755 Mean dependent var 8.504486
Adjusted R-squared 0.987951 S.D. dependent var 1.037058
S.E. of regression 0.113834 Akaike info criterion -1.416379
Sum squared resid 0.362831 Schwarz criterion -1.277606
Log likelihood 24.95388 F-statistic 1230.946
Durbin-Watson stat 1.295173 Prob(F-statistic) 0.000000
可见,K1和L的t值显著,且系数符合经济意义。从经济意义上讲,资本每增加一单位,都可以使实际GDP相应增加。另外,修正可决系数为0.987951,F值为1230.946,明显通过了F检验。且K1和L的P检验值为0,均小于0.05,所以通过了P值检验。
通过对以上模型的可决系数 、调整可决系数 、F检验的比较,明显的 ,该模型最优。因此,选用该模型为以各城市同一时期的GDP为被解释变量,以其它可量化横截面数据作为解释变量建立的最优多元线性回归模型。
六、总结
综上所述,我们用截面数据拟合的模型成功的反映各城市同一时期的GDPY1与就业人数L(万人)和各地区剔除价格影响因素即商品零售价格指数P(上年=100)的资本形成总额K1(亿元)间的数量关系,是一个成功的模型。从模型中看出,各城市同一时期的GDPY1与就业人数L(万人)和各地区剔除价格影响因素即商品零售价格指数P(上年=100)的资本形成总额K1(亿元)有非常密切的关系,与柯布-道格拉斯 (C-D)生产函数密切吻合,验证了柯布-道格拉斯 (C-D)生产函数的正确。
参考文献:
1、《国民经济核算——国家统计年鉴2007》
2、《价格指数——国家统计年鉴2007》
3、《中国国内生产总值核算》,作者:许宪春 编著,
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。